GPT-1
GPT-1,全称基于转换器的生成式预训练模型1()是继2017年Google推出Transformer架构后,OpenAI推出的第一个大型语言模型[3]。2018年,OpenAI发布了一篇名为《通过生成式预训练提高语言理解能力》()的论文,其中介绍了该初期模型以及基于转换器的生成式预训练模型的总体概念[4] 。
| 原作者 | OpenAI |
|---|---|
| 首次发布 | 2018年2月 |
| 当前版本 |
|
| 源代码库 | |
| 由…取代 | GPT-2 |
| 类型 | |
| 许可协议 | MIT[2] |
| 网站 | openai |
| 机器学习与 |
|---|
在此之前,表现最佳的神经网络自然语言处理模型主要采用依靠大量手动标记数据的监督学习。这种依赖于监督学习的方法限制了它们在未经精细标注的数据集上的应用,并使训练超大模型相当耗时且开支非常昂贵[5][6];许多语言(例如斯瓦希里语或海地克里奥尔语)由于缺乏能创建起语料库的文本资料,导致模型难以对其进行翻译和解释[6]。相比之下,GPT采用了“半监督”方法,包含两个阶段:无监督的生成式“预训练”阶段,使用目标函数来设置初始参数;以及有监督的判别式“微调”阶段,将这些参数在目标任务上进行微调[5]。
与之前基于注意力增强的循环神经网络(RNN)技术相比,GPT采用的Transformer架构为模型提供了比循环机制更加结构化的记忆;使其拥有“跨多样任务的稳健传输性能”[5]。
选择BookCorpus的原因
选择BookCorpus作为训练数据集的一部分原因是其中包含了长篇连续文本,有助于模型学习处理长距离信息[7]。该数据集包含来自各种流派的7,000多本未发表的小说。当时其他可用的数据集虽然更大,但缺乏这种长距离结构(在句子级别上被“洗牌”)[5] 。
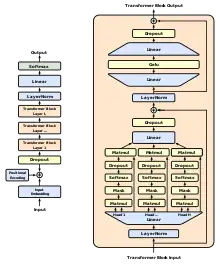
架构
GPT-1采用了十二层的仅解码变换器,使用了12个掩码的自注意力头,每个头有64个维度状态(总共768个维度状态)。GPT-1采用了Adam优化算法,而非简单的随机梯度下降;学习率在前2000次更新中线性增加到最大值2.5×10−4,然后通过余弦调度减少到0[5]。
尽管微调是针对特定任务进行调整的,但其预训练过程并没有调整;为了执行各种任务,只对其底层的与任务无关的模型架构进行了最小的更改[5]。尽管如此,GPT-1仍然在多个语言处理任务中改进了以往的基准,在许多任务上的表现优于面向任务的判别式训练模型[5]。
性能与评估
在自然语言推理(又称文字蕴涵)任务中,GPT-1在QNLI(维基百科条目)和MultiNLI(转录的演讲、流行小说和政府报告等来源)两个数据集上分别比以往最佳结果提升了5.8%和1.5%。该任务评估的是其解释一对句子,并将它们之间的关系分类为“蕴涵”、“矛盾”或“中立”的能力[5][8]。在与问题回答和常识推理相关的两个任务上,GPT-1也优于以前的模型,分别在RACE(中学和高中考试题目的数据集)上提升了5.7%[9],在Story Cloze Test上提升了8.9%[10]。
在语义相似性(又称释义检测)任务方面,GPT-1预测两个句子是否语义对等的能力比以往最佳结果提高了4.2%,该任务使用了Quora问题对(Quora Question Pairs,QQP)数据集[5]。
在使用语言可接受性语料库(,CoLA)进行文本分类任务时,GPT-1获得了45.4分,而以前最好的得分是35.0[5]。在GLUE(一种多任务测试)上,GPT-1取得了72.8的总体得分,优于以前的最好成绩68.9分[11]。
参考资料
- https://huggingface.co/transformers/pretrained_models.html.
- . GitHub. [2023-03-13]. (原始内容存档于2023-03-11).
- Vaswani, Ashish; Shazeer, Noam; Parmar, Niki; Uszkoreit, Jakob; Jones, Llion; Gomez, Aidan N.; Kaiser, Lukasz; Polosukhin, Illia. . 2017-06-12. arXiv:1706.03762
 [cs.CL].
[cs.CL]. - . [2023-04-29]. (原始内容存档于2023-04-15).
- Radford, Alec; Narasimhan, Karthik; Salimans, Tim; Sutskever, Ilya. (PDF). OpenAI: 12. 2018-06-11 [2021-01-23]. (原始内容存档 (PDF)于2021-01-26).
- Tsvetkov, Yulia. (PDF). Carnegie Mellon University. 2017-06-22 [2021-01-23]. (原始内容存档 (PDF)于2020-03-31).
- Zhu, Yukun; Kiros, Ryan; Zemel, Richard; Salakhutdinov, Ruslan; Urtasun, Raquel; Torralba, Antonio; Fidler, Sanja. . 2015-06-22. arXiv:1506.06724 [cs.CV].
# of books: 11,038 / # of sentences: 74,004,228 / # of words: 984,846,357 / mean # of words per sentence: 13 / median # of words per sentence: 11
- Williams, Adina; Nangia, Nikita; Bowman, Samuel. (PDF). Association for Computational Linguistics. 2018-06-01 [2021-01-23]. (原始内容存档 (PDF)于2020-02-11).
At 433k examples, this resource is one of the largest corpora available for natural language inference (a.k.a. recognizing textual entailment), [...] offering data from ten distinct genres of written and spoken English [...] while supplying an explicit setting for evaluating cross-genre domain adaptation.
- Lai, Guokun; Xie, Qizhe; Hanxiao, Liu; Yang, Yiming; Hovy, Eduard. . 2017-04-15. arXiv:1704.04683 [cs.CL].
- Mostafazadeh, Nasrin; Roth, Michael; Louis, Annie; Chambers, Nathanael; Allen, James F. (PDF). Association for Computational Linguistics. 2017-04-03 [2021-01-23]. (原始内容存档 (PDF)于2020-11-22).
The LSDSem’17 shared task is the Story Cloze Test, a new evaluation for story understanding and script learning. This test provides a system with a four-sentence story and two possible endings, and the system must choose the correct ending to the story. Successful narrative understanding (getting closer to human performance of 100%) requires systems to link various levels of semantics to commonsense knowledge.
- Wang, Alex; Singh, Amanpreet; Michael, Julian; Hill, Felix; Levy, Omar; Bowman, Samuel R. . 2018-04-20. arXiv:1804.07461 [cs.CL].